Usage¶
esub¶
To run esub use the following syntax:
$ esub PYTHON-EXECUTABLE [further esub arguments] [arguments passed to EXECUTABLE]
Note that as long as you do not start jobs with the same job_name from the same working directory esub will never confuse your jobs so you can run as many as you want. If you still start multiple jobs with the same name from the same directory it will not crash your jobs but the log files might just be messed up since all jobs write to the same log.
A short explanation of the arguments:
PYTHON-EXECUTABLE¶
esub will search in this file for the main function. Per default the main function is named ‘main’, but its name can be changed using the –main_name flag. In addition esub will search for some special functions namely: resources, watchdog, merge, check_missing and setup. The file can also contain other functions but esub will ignore them. For an example of how such a file should look please have a look at esub executable example.
Further esub arguments¶
esub has a variety of additional arguments that we describe here
mode:
default: run
choices: run, jobarray, mpi, run-mpi, run-tasks
The mode in which to operate. See below under esub’s modes for a description.
function:
default: main
choices: main, watchdog, merge, rerun_missing, check_missing, all
The functions that should be executed. See below under esub’s functions for a description.
main_name:
default: main
The name of the main function in the executable file that esub will search for.
tasks:
default: 0
Task string from which the task indices are parsed. Either single index, list of indices (eg 0,1,2), range (eg 0 > 10, first is inclusive, last is exclusive) or a path to a file containing such a list or range.
n_jobs:
default: 1
The number of jobs to request for the main jobs (watchdog and merge are always submitted as a single job running all the tasks). The tasks are split equally over the n_jobs.
job_name:
default: job
Individual name for this job (determines name of the log files and name of the job submitted to a queing system).
source_file:
default: source_esub.sh
Optionally provide a shell file which gets sourced before running any job (used to load modules, declaring environemental variables and so on when submitting to a queing system). See source file example for an example of such a script.
dependency:
default: ‘’
A dependency string that gets added to the dependencies (meant for chaining multiple jobs after each other, see epipe).
system:
default: bsub
choices: bsub, slurm
Type of the queing system.. Note that SLURM support is very experimental and should be used with a lot of caution.
max_njobs:
default: -1
Number of jobs that are allowed to run at the same time. Per default no restrictions.
log_dir:
default: current working directory
Location where esub will write the logs to.
test:
default: False
If True jobs are not submitted but only printed.
discard-output:
default: False
If True all stdout and stderr is redirected to /dev/null
batchsize:
default: 100000
If jobarray has more than batchsize tasks it will automatically be broken down into smaller arrays.
additional_args:
Provide comma separated lines that get added to the run files when using SLURM mode.
additional_bsub_args:
Provide an additional string that gets appended to the bsub command when using IBMs LSF system.
esub_verbosity:
default: 3
Controls the verbosity of esub. Allows values from 0 - 4 with 4 being the most verbose.
Resource allocation (overwrites resources function in executable file):
main_memory:
default: 1000
Memory allocated per core for main job in MB.
main_time:
default: 4
Job run time limit in hours for main job.
main_time_per_index:
default: None
Job run time limit in hours for main job per index, overwrites main_time if set.
main_scratch:
default: 2000
Local scratch allocated for main job (only relevant if node scratch should be used).
watchdog_memory:
default: 1000
Memory allocated for watchdog job in MB.
watchdog_time:
default: 4
Job run time limit in hours for watchdog job.
watchdog_scratch:
default: 2000
Local scratch allocated for watchdog job (only relevant if node scratch should be used).
merge_memory:
default: 1000
Memory allocated for merge job in MB.
merge_time:
default: 4
Job run time limit in hours for merge job.
merge_scratch:
default: 2000
Local scratch allocated for merge job (only relevant if node scratch should be used).
main_n_cores_per_job:
default 1:
Number of cores available for each main job.
watchdog_n_cores:
default: 1
Number of cores available for the watchdog job.
merge_n_cores:
default: 1
Number of cores available for the merge job.
mpi_merge:
default: False
If True merge job is submitted as MPI job.
mpi_watchdog:
default: False
If True watchdog job is submitted as MPI job.
Arguments passed to EXECUTABLE¶
All arguments unknown to esub are automatically passed on to the functions in the PYTHON-EXECUTABLE file in form of an argparse object.
esub’s functions¶
The python executable file must contain at least a main function. Additionaly esub will search for the following functions: resources, watchdog, merge. The file can also contain other functions but esub will ignore them. If –function=all is given esub will all the functions. Additonaly, the built in function rerun-missing will be ran as well. Rerun-missing checks if some of the main functions have failed and will rerun them before the merge function is executed (this was introduced due to some clusters having random memory leaks which can cause a few jobs to fail in an unpredictable way). For an example of how such a file should look please have a look at esub executable example.
Main function:
The main function. It receives a list of task indices as an argument and will run on each index one after another. If multiple cores are allocated esub will split the list equally to the different cores.
Watchdog function:
The watchdog function runs on a single core. Depending on the mode it will run alongside the main functions or after the main functions have finished (in this case it serves the same purpose as the merge function). It runs on the full list of all task indices. The watchdog function is meant for collecting output files that the main functions are writting on the fly (or other things you can come up with :).
Merge function:
The merge function runs on a single core. It will always only start when all the main functions and the watchdog function have already finished. It runs on the full list of all task indices. The merge function is meant for postprocessing of the data produced by the main and watchdog functions, such as calculating means and errors.
Resources function:
The resources function can be used to assign the computational resources for the jobs (see esub executable example) for an example of the syntax). It does not have to be declared to be ran explicitly. If it is present in the executable file it will be ran.
Setup function:
Yet another special function. If esub finds a function called setup in your executable it will run it first before doing anything else. This is useful to create output directories for example.
check missing function:
Sometimes it is not good enough to just rerun all jobs that failed but one also wants to check if some jobs produced corrupted output and rerun those jobs as well. The check_missing function can be used to do so. The function should return a list of job indices that should be reran.
esub’s modes¶
What makes esub very convenient to use is that you write your executable file only once and it can then be ran in all different modes of esub. This means you do not have to worry about parallelization and so on. Here we present the different modes of esub:
run:
In run mode everything is ran on a single core serially and locally (no job is submitted to the queing system). This mode is meant for debugging of your code or lightweight code that you just want to test on your own computer or so. Ignores the n_jobs parameter.

run-tasks:
The run-tasks mode allows you to split the load of the main function onto multiple local cores. This mode is meant to run not so heavy code on your local machines or small servers using the power of multiprocessing. Note that the cores are independent -> There is no communication between the cores
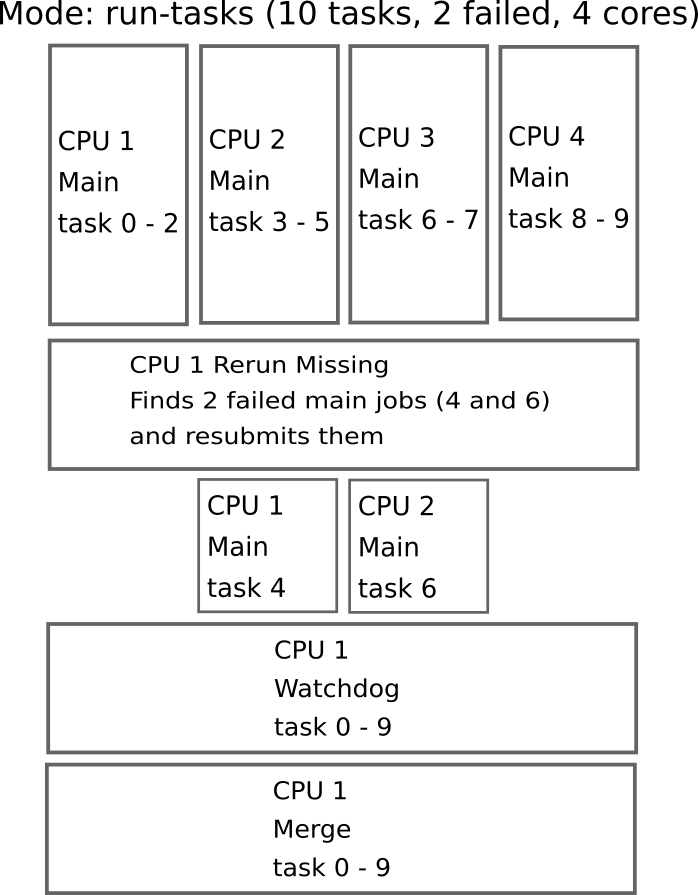
run-mpi:
The run-mpi mode allows you to run a local MPI job. It will run just a single main job (ignoring the tasks parameter) with index 0 but on all the cores. This mode is meant to run lightweight MPI jobs on your local machine or on a small server such as MCMC chains for example. Note that in MPI mode the cores can communicate with each other. NOTE: you need a working MPI environement set up in order to use this mode.

mpi:
This mode assumes that there is a queing system present. It will submit a single MPI job running only on the index 0 (ignoring the tasks parameter) to the queing system. This mode is meant for heavy MPI jobs such as long MCMC sampling for example.

jobarray:
This mode assumes that there is a queing system present. It will split the load of the main jobs equally onto the n_jobs. This mode allows you to easily parallelize your jobs. There is no communication between the cores though. Note that jobarrays will go through the queing system much faster than MPI jobs, so unless you absolutely need communication between the cores this mode should be prefered.

epipe¶
epipe is a subtool of esub-epipe that allows you to chain multiple esub jobs after each other. This is very useful if you want to run a long pipeline on a cluster.
The only thing needed to run epipe is a YAML file containing the information about the different jobs that should be ran.
Each job instance consists of a job name, the esub command that should be submitted as well as some optional dependencies (can either be names of other jobs or job IDs). The job will only start running once the jobs listed in its dependencies have finished.
epipe also allows you to specify loops and the loop index can be passed to the commands.
One more feature is that you can specify global variables which can then be inserted into the commands.
The general syntax for running epipe is:
$ epipe PIPELINE.yaml --epipe_verbosity=3
The epipe_verbosity argument controls the verbosity of epipe. Please refer to the epipe pipeline example file for an example of how such a file should look like.
The ESUB_LOCAL_SCRATCH environement variable¶
When running your code on large computer clusters it is often advisable to store intermediate data products on the local scratch on the computer nodes. You can set the ESUB_LOCAL_SCRATCH environement variable (using the esub source script for example) to point to the local scratch and esub will automatically change its current working directory there upon submission of the jobs.
Convenience scripts¶
There are two scipts to facilitate job management, both located in esub.scripts: check_logs and send_cmd.
check_logs¶
Can be executed via
$ python -m esub.scripts.check_logs --dirpath_logs=[directory to check]
Checks all esub log files located in the given directory and prints the names of the log files which contain unfinished jobs.
send_cmd¶
Can be executed via
$ python -m esub.scripts.send_cmd --dirpath_logs=[directory to check] --cmd=[cmd to send] --log_filter=[logs to include]
Sends a command to all jobs logged in all log files located in the given directory. The command could for example be “bkill” to terminate these jobs. Optionally, the log_filter argument allows to only include jobs logged in files whose names contain a given string.